21. 一位機器學習工程師正在優化公司內部的 RAG 法律文件問答系統。近期因營運 成本壓力,公司要求在不更換模型且不影響回答品質的前提下,將整體 token 成 本降低至目前的 60%,且目前成本主要集中於輸入 tokens。工程師在檢查系統後, 盤點出目前的使用情況如下:
◆使用模型:GPT-4o(輸入$5/1M tokens、輸出 $15/1M tokens)
◆每次查詢:將前 10 筆檢索文件區塊全部加入 Prompt(每塊約 600 tokens)
◆System Prompt:每次請求均包含約 500tokens 的公司背景說明
◆對話機制:保留完整對話歷史,平均累積約 8,000tokens
◆每日查詢量:約 5,000 次
◆平均輸出:約 300tokens/次
在上述限制與系統現況下,請問下列哪一項優化組合,最能在維持回答品質的前提下有效降低 token 成本? (A)將輸出 max_tokens 從 1,000 壓縮至 200,強制模型給出更短的回答,以降低輸 出費用; (B)將 System Prompt 改為 Prompt Caching 或靜態前綴重用,並對對話歷史實作摘 要壓縮,以保留語意而非完整對話; (C)將所有查詢改為 Batch API 模式送出,透過非同步處理降低單次費用; (D)在 Prompt 中明確要求模型「回答時盡量簡短」,透過指令引導模型自行縮減輸 出長度
 阿摩線上測驗
登入
阿摩線上測驗
登入
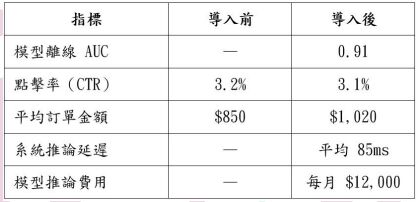 (A)僅依賴離線指標 AUC 判斷模型成效,忽略線上業務指標(如 CTR 與營收) 的變化,可能導致錯誤結論; (B)AUC 已達 0.91,代表模型排序能力優異,即使 CTR 略為下降,仍可視為推薦 品質提升; (C)CTR 從 3.2%降至 3.1%,顯示模型效果變差,應立即還原(Rollback)至舊模 型; (D)平均訂單金額提升至$1,020,代表模型已成功優化營收,因此無需考慮其他指 標
(A)僅依賴離線指標 AUC 判斷模型成效,忽略線上業務指標(如 CTR 與營收) 的變化,可能導致錯誤結論; (B)AUC 已達 0.91,代表模型排序能力優異,即使 CTR 略為下降,仍可視為推薦 品質提升; (C)CTR 從 3.2%降至 3.1%,顯示模型效果變差,應立即還原(Rollback)至舊模 型; (D)平均訂單金額提升至$1,020,代表模型已成功優化營收,因此無需考慮其他指 標